


 국내 의과대학 본과생들이 실제 임상 증례 분석에서 인공지능(AI)이 의료진과 비교해 더 높은 판단 정확도를 보일 수 있음을 확인했다.
국내 의과대학 본과생들이 실제 임상 증례 분석에서 인공지능(AI)이 의료진과 비교해 더 높은 판단 정확도를 보일 수 있음을 확인했다.
용인세브란스병원(병원장 김은경) 심장내과 배성아·정신건강의학과 박진영 교수와 연세의대 본과 4학년 정재원·김현재 학생 연구팀은 오픈AI 멀티모달 및 추론 AI 모델(GPT-4o, o1)의 임상 판단 정확도를 의료진 응답과 비교·분석한 연구 결과를 발표했다.
이번 연구는 교수 지도 아래 의대 본과생들이 연구 설계부터 데이터 분석, 논문 작성까지 전(全) 과정을 주도했다는 점에서 의학교육과 AI 의료 연구 측면에서 의미 있는 성과로 평가된다.
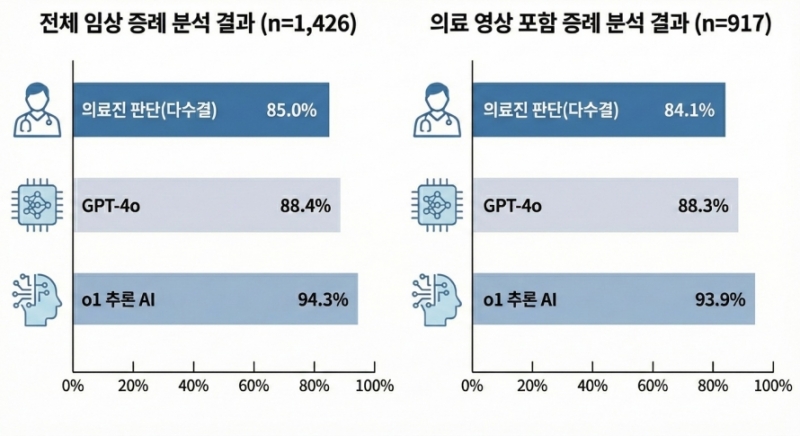
연구팀은 2011년부터 2024년까지 의료교육 플랫폼 ‘메드스케이프(Medscape)’에 공개된 1426건의 임상 증례를 분석했다.
각 증례에는 환자 상세한 병력을 비롯해 신체 검사 소견, 혈액 검사 결과는 물론 X-ray(엑스레이), CT, MRI, 초음파, 심전도, 병리 슬라이드 등 총 917건의 의료영상이 포함돼 실제 임상에서 접하는 복잡한 진단 상황을 반영했다.
분석 결과, 다수 의료진이 선택한 답안 정확도는 85.0%였고 GPT-4o는 88.4%, 최신 추론 모델인 o1은 94.3%를 기록했다. 의료영상이 포함된 증례만을 별도로 분석한 경우에도 두 모델 모두 유의미하게 의료진보다 높은 정확도를 보였다.
AI가 의료진 판단 대체 아닌 복잡한 임상 상황에서 의사 결정 보조하고 안정성 높이는 도구
특히 o1 모델은 진단(92.6%), 질병 특성 파악(97.0%), 검사 계획(92.6%), 치료 방향 설정(94.8%) 등 모든 임상 판단 영역에서 90% 이상의 정확도를 유지했다. 또한 내과·외과·정신과 등 전공 분야와 관계없이 안정적인 성능을 나타냈다.
연구팀은 동일한 증례를 5회 반복 분석해 AI 모델 판단 일관성도 검증했다. GPT-4o는 86.2% 증례에서, o1은 90.7% 증례에서 5번 모두 정확한 답을 제시했다.
이는 AI 모델이 단순한 우연이나 무작위 선택이 아닌 체계적인 추론을 바탕으로 답을 도출하고 있다는 것을 보여주는 결과다.
연구를 주도한 학생들은 “1년 이상 데이터를 수집하고 분석하며 통계를 배우는 과정이 쉽지 않았지만, AI가 실제 임상에서 어떻게 활용될 수 있을지 직접 확인한 것이 가장 큰 보람”이라며 “학부생이라도 연구에 관심이 있으면 교수님께 직접 연락해 지도받을 수 있는 환경이 도움이 됐다”고 말했다.
배성아·박진영 교수는 “이번 연구는 AI 모델이 텍스트와 의료 영상을 통합해 실제 임상 수준 판단을 내릴 수 있다는 것을 객관적으로 입증한 사례”라며 “이는 AI가 의료진 판단을 대체한다기보다는 복잡한 임상 상황에서 의사 결정을 보조하고 안정성을 높이는 도구로 활용될 수 있음을 보여준다”고 밝혔다.
한편, 이번 연구결과는 국제학술지 Medicine(Baltimore) 2026년 1월호에 게재됐다.
???? (AI) .
( ) 4 AI AI (GPT-4o, o1) .
, () AI .
2011 2024 (Medscape) 1426 .
, X-ray(), CT, MRI, , , 917 .
, 85.0% GPT-4o 88.4%, o1 94.3% . .
AI
o1 (92.6%), (97.0%), (92.6%), (94.8%) 90% . .
5 AI . GPT-4o 86.2% , o1 90.7% 5 .
AI .
1 , AI .
AI AI .
, Medicine(Baltimore) 2026 1 .










